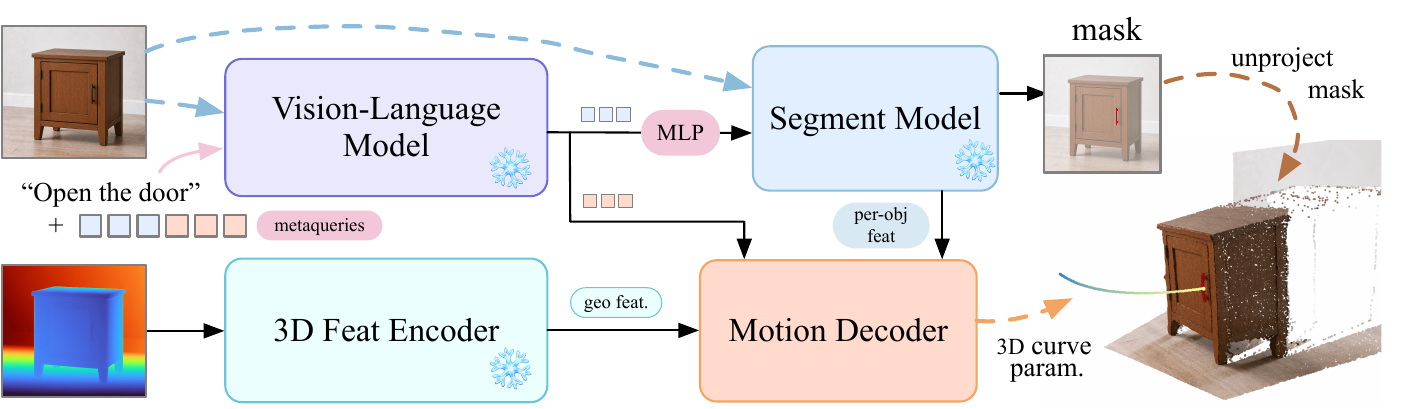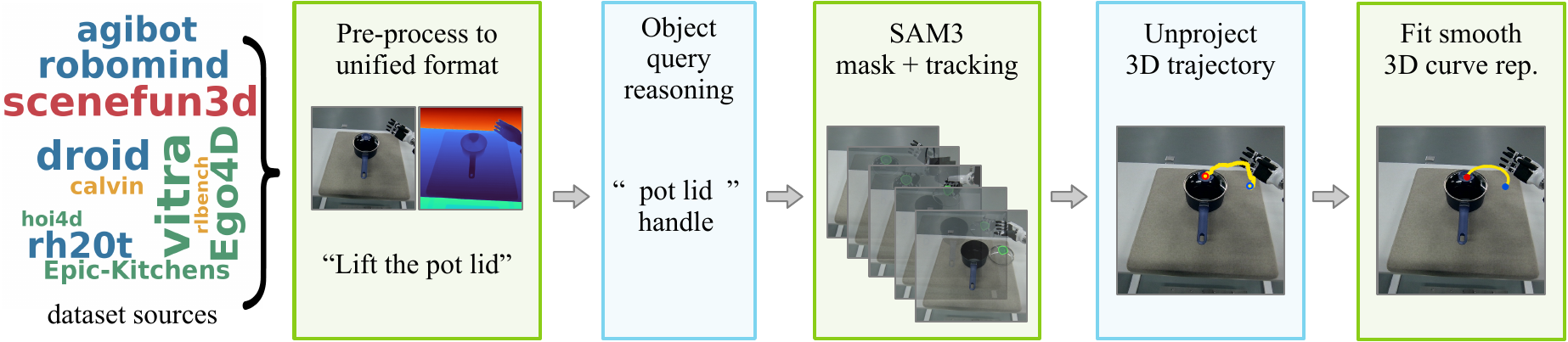
Where + How for Functionality Understanding
A single forward pass predicts both a task-conditional functional mask (where to interact) and a 3D post-contact motion curve (how to interact).
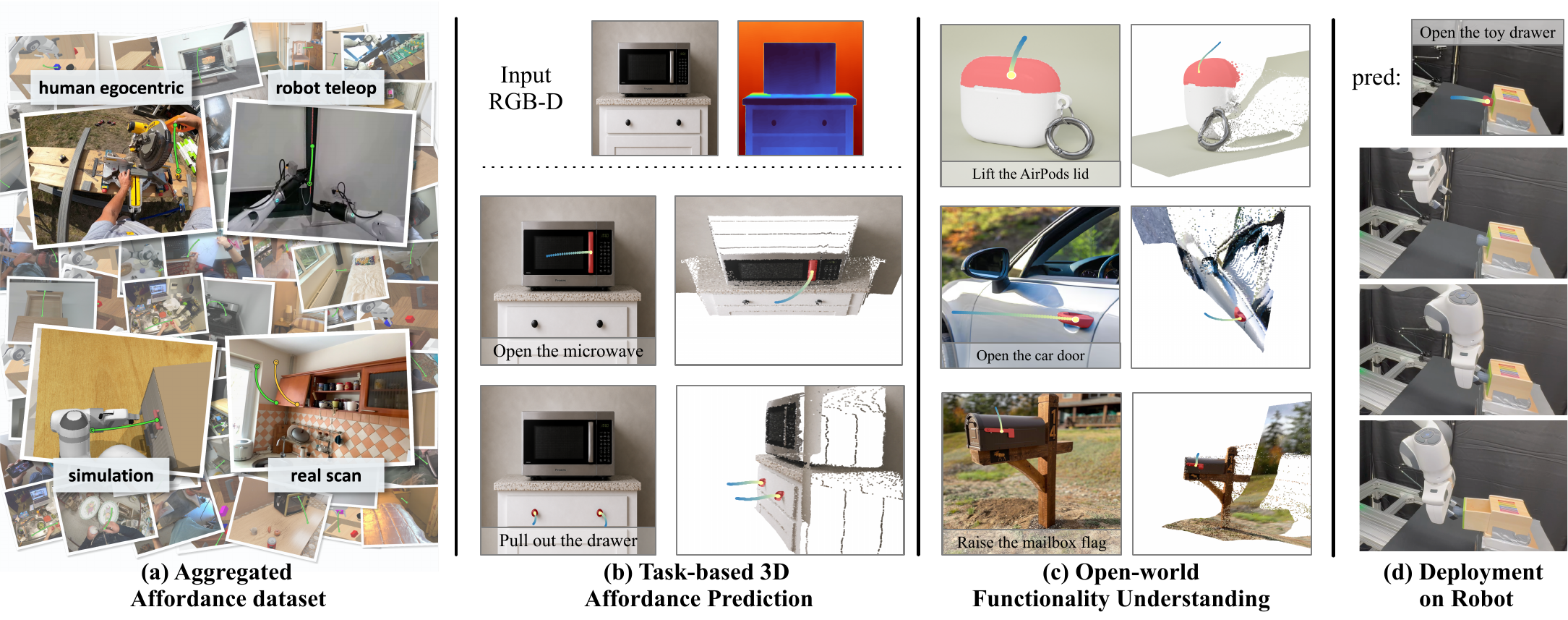
SOTA Affordance Segmentation
+23.9 / +26.3 mean gIoU/cIoU over the best baseline, across 8 test sets from 4 affordance benchmarks.
Largest Public Affordance Data
One of the largest public affordance datasets to date: robot, human egocentric, simulation, and real-world scan data.
We present AFUN, a step toward an affordance foundation model for functionality understanding. From a single RGB-D observation and a language task description, AFUN predicts a task-conditional functional mask (where to interact) and a 3D post-contact motion curve (how to interact). To support open-world generalization, we build a large-scale standardized data pipeline that converts heterogeneous robot, human, simulation, and real-world scan data into a shared affordance schema with language, masks, and object-centric 3D motion labels.